Are you a Quiet Speculation member?
If not, now is a perfect time to join up! Our powerful tools, breaking-news analysis, and exclusive Discord channel will make sure you stay up to date and ahead of the curve.
Finally, it's time for everyone's favorite part of the banlist test: the experimental data. After playing 500 matches with GB Elves over several months, I can finally put some data to the speculation about the impact of unbanning Green Sun's Zenith. I will be revealing the hard numbers and their statistical significance. As always, these data are meant to explore the impact of the tested card, but I can't test every single impact, metagame shift, or other permutation that could arise.
If you're just joining us, be sure to first read the Experimental Setup for this project.

Boilerplate Disclaimers
Contained are the results from my experiment. It is entirely possible that repetition will yield different results. This project models the effect that the banned card would have on the metagame as it stood when the experiment began. This result does not seek to be definitive, but rather provide a starting point for discussions on whether the card should be unbanned.
Meaning of Significance
When I refer to statistical significance, I really mean probability; specifically, the probability that the differences between a set of results are the result of the trial and not normal variance. Statistical tests are used to evaluate whether normal variance is behind the result, or if the experiment caused a noticeable change in result. This is expressed in confidence intervals determined by the p-value from the statistical test. In other words, statistical testing determines how confident researchers are that their results came from the test and not from chance. The assumption is typically "no change," or a null hypothesis of H=0 (though there are exceptions).
 If a test yields p > .1, the test is not significant, as we are less than 90% certain that the result isn't variance. If p < .1, then the result is significant at the 90% level. This is considered weakly significant and insufficiently conclusive by most academic standards; however, it can be acceptable when the n-value of the data set is low. While you can get significant results with as few as 30 entries, it takes huge disparities to produce significant results, so sometimes 90% confidence is all that is achievable.
If a test yields p > .1, the test is not significant, as we are less than 90% certain that the result isn't variance. If p < .1, then the result is significant at the 90% level. This is considered weakly significant and insufficiently conclusive by most academic standards; however, it can be acceptable when the n-value of the data set is low. While you can get significant results with as few as 30 entries, it takes huge disparities to produce significant results, so sometimes 90% confidence is all that is achievable.
p < .05 is the 95% confidence interval, which is considered a significant result. It means that we are 95% certain that any variation in the data is the result of the experiment. Therefore, this is the threshold for accepting that the experiment is valid and models the real effect of the treatment on reality. Should p < .01, the result is significant at the 99% interval, which is as close to certainty as you can get. When looking at the results, just look at the p-value to see if the data is significant.
Significance is highly dependent on the n-value of the data. The lower the n, the less likely it is that the result will be significant irrespective of the magnitude of the change. With an n of 30, a 10% change will be much less significant than that same change with n=1000. This is why the individual results frequently aren't significant, even when the overall result is very significant.
Overall Results
Just as a reminder from last week, I played 500 total matches, 250 per deck. I switched decks each match to level out any effect skill gains had on the data. Play/draw alternated each match, so both decks spent the same time on the draw and play.
Here's the data, overall results and bonus stats first, individual results afterward.
- Total Control Wins - 119 (47.6%)
- Total Test Wins - 148 (59.2%)
- Overall Win % - 53.4%
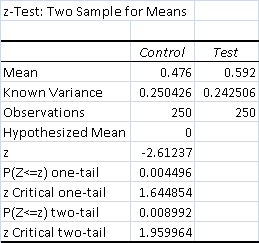
The data show that adding GSZ to GB Elves had a strongly significant positive effect on its win percentage. The data is significant at the 99% confidence interval, indicating a high degree of certainty.
From these data, it is obvious that GSZ is a powerful card that would benefit decks that could have a strong impact on Modern. Exactly what that impact would be isn't obvious from this result, as an overall win increase is somewhat meaningless in a vacuum. To really understand the impact requires going into the details, though note the significance problems I mentioned above apply to the individual results.
Interesting Additional Data
As always, I record anything that seems interesting or potentially relevant during testing. In the past, that has included data such as the average turn I played the test card, or cascade stats. This time is a bit different because I changed what I was looking for. In particular, the false start with UW led me to keep track of how many times I cast the same GSZ. What exactly these data mean depends on perspective, because there are many ways to look at them, but they're important to the overall picture of GSZ.
- Number of games with multiple GSZ cast - 568
- Times drawing and casting the same GSZ more than once per game - 216
- Same casts against UW - 114
- Same casts against Storm - 5
- Same casts against Tron - 53
- Same casts against Humans - 16
- Same casts against GDS - 28
- Total GSZ for 0 casts - 129
As might be expected, the longer the games went, the more times I redrew and recast GSZ. There has to be some model for this effect, but I couldn't find one. If anyone knows, do let me know.
Deck by Deck
The general effect of GSZ on GB Elves was to make the deck more consistent while also slowing it down. There were fewer explosive wins, but I also experienced fewer floodouts. GSZ usually took a turns worth of mana that could have been used flooding the board with dorks, but it also meant that I actually hit payoff cards more often. This is reflected in the average winning turn stats:
- Average control win turn - 4.24
- Average test win turn - 4.95
I should also note that the control Elves deck was capable of actually winning on turn three several different ways (Elvish Archdruid and Ezuri, Renegade Leader, Ezuri and Devoted Druid, Heritage Druid hand dump into lords, etc.), while the test deck really only had two: flooding the board and curving out. As a result, most of test Elves's turn three wins were concessions rather than actual wins. The test data will be reported in the order the testing was finished.
UW Control
I discussed this matchup extensively last week, and that article is critical to understanding this section. After the false start, I expected this result to be far closer than previously shown. I still thought, especially considering my opponent's assessment of the matchup, that Elves would be favored, but I didn't expect it to remain this favored.
- Total Control Wins - 25 (50%)
- Total Test Wins - 35 (70%)
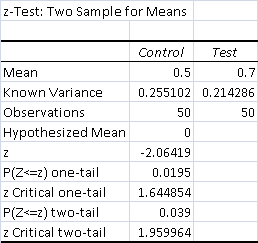
The result is a significantly positive result for Elves's win percentage. P<.05 so the data are significant at the 95% confidence interval, and nearly the 99% level.
The control deck did better than in the first test despite how the UW pilot adjusted their play and strategy. This is attributable to Elvish Clancaller acting close enough to Goblin Matron for that old problem to resurface. Game 1 proved much harder for UW regardless of GSZ as a result. The test deck's decreased win rate is the result of UW actually understanding the matchup and playing accordingly. Baneslayer Angel was very hard to race if it was set up with Terminus. Search for Azcanta was the most important card for UW, as it helped dig for Angel.
Storm
Storm vs. Elves, especially game 1, is a straight-up race, which is also how I understand the Legacy matchup goes. Storm can interact with Elves, but it's often unnecessary, as Storm can combo turn three more easily and more often than Elves. After board, Elves has relevant interaction and a hate card, while Storm usually goes for extra answers to Damping Sphere.
- Total Control Wins - 21 (42%)
- Total Test Wins - 18 (36%)
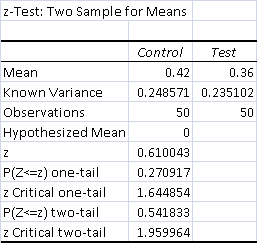
The result is not significant. Despite the test win percentage decline, there is no reason to think that is anything other than normal variance. Therefore, GSZ did not impact the matchup.
The decline is largely attributable to the removal of Devoted Druid slowing down test Elves. Even when I couldn't combo off, Storm still had to respect the possibility that I could just kill them, and had to take a turn off to not die. The extra Damping Sphere in test Elves kept the overall matchup much closer than I expected.
Mono-Green Tron
GR Tron used to crush decks like Elves when it ran 4 Pyroclasm main. With GR's decline, Tron is more vulnerable to swarm strategies. Ugin, the Spirit Dragon is still usually game over when it resolves.
- Total Control Wins - 23 (46%)
- Total Test Wins - 30 (60%)
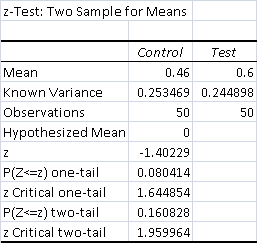
The result is weakly positively significant. While test Elves's win percentage increased, it did not make it to 95% confidence. It did cross 90% confidence, so the result cannot be fully discounted.
 The matchup was decided by Oblivion Stone and Ugin. Popping a single Stone wasn't always enough to stabilize thanks to all the tutors in Elves, but buying the space to cantrip into Ugin was still great. However, if Elves got in a strong enough hit before Ugin, it was far easier for the test deck to still win by tutoring for Shaman of the Pack. Grafdigger's Cage and Damping Sphere weren't major factors because both decks brought in artifact destruction and could just work through the hate naturally.
The matchup was decided by Oblivion Stone and Ugin. Popping a single Stone wasn't always enough to stabilize thanks to all the tutors in Elves, but buying the space to cantrip into Ugin was still great. However, if Elves got in a strong enough hit before Ugin, it was far easier for the test deck to still win by tutoring for Shaman of the Pack. Grafdigger's Cage and Damping Sphere weren't major factors because both decks brought in artifact destruction and could just work through the hate naturally.
I believe that the Tron matchup would be more positive for Elves in a GSZ world because I really didn't push the tutoring aspect in my deck. GSZ proved to be a workhorse tutor that I fired off for value all the time. This let Chord of Calling be a specialist tool. I could have played more tutor targets like Selfless Spirit or Phyrexian Revoker. Chording for those to protect against Stone and Ugin respectively would have greatly improved the matchup.
Humans
I expected Humans to struggle because in my experience, go-wide creature strategies are very good against Humans's go-tall strategy. The disruptive package is also weak against creature decks. It wasn't as bad as I thought against the control version because Meddling Mage is great at stopping payoff cards, and Izzet Staticaster can dismantle a board.
- Total Control Wins - 27 (54%)
- Total Test Wins - 35 (70%)
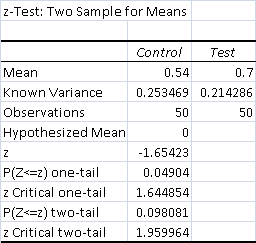
The result is a significant positive result for test Elves's win percentage. The data are significant at the 95% confidence interval.
 GSZ gave Elves far more ways to get around Mage and hit the payoff cards to overwhelm Humans. The best strategy for Humans proved to be an airborne attack, which meant keeping in Kitesail Freebooter. Subsequently, it was plausible for Humans to take the only Chord or Collected Company in the control deck's hand, then Mage the other payoff card and successfully race the random beaters. That plan became almost impossible with the addition of GSZ.
GSZ gave Elves far more ways to get around Mage and hit the payoff cards to overwhelm Humans. The best strategy for Humans proved to be an airborne attack, which meant keeping in Kitesail Freebooter. Subsequently, it was plausible for Humans to take the only Chord or Collected Company in the control deck's hand, then Mage the other payoff card and successfully race the random beaters. That plan became almost impossible with the addition of GSZ.
Staticaster was very good in games where Humans was winning, but was overall inadequate. If Elves got out a few lords or Ezuri and lots of mana, it was terrible. Humans stole a few games off copying Staticaster and chewing through the lords, but it was a huge struggle. Dismember was a wash in races often enough in testing that we didn't board it in.
Grixis Death's Shadow
This proved to be a very swingy test. Death's Shadow decks are known for shredding opposing hands, while Elves is great at dumping theirs. The match was about Grixis having a clock with enough life to survive a counterswing, and typically turned into a waiting game for both sides. Elves would get in chip shots then and then try to win with a single big attack. If there was a Shadow or Gurmag Angler out, I would hold back until certain of victory. Grixis relied heavily on finding Temur Battle Rage.
- Total Control Wins - 23 (46%)
- Total Test Wins - 30 (60%)
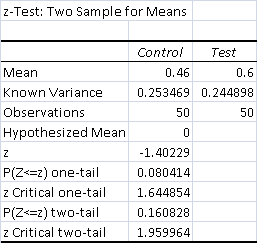
The data is the same as against Tron, and so my conclusion is the same: weakly positively significant.
The lack of sweepers in the Grixis list really hurt, and it struggled to stabilize the board. The extra tutor made crunching through blockers far easier to manage.
Data Point
The data show that the slower the deck Elves faced, the more opportunity GSZ has to make an impact. It also did well in attrition-based matchups, finding ways to rebuild after removal. However, that's not the full story of the testing. Next week, I will present the less tangible lessons from testing and my thought on GSZ's viability in Modern.

Small nitpick, azcanta can’t find baneslayer
Interesting results – hard to say if it’s a reasonable jump in the competitiveness of elves or if it’s too much and busted card is busted. Would elves be tier one with this? Would it be oppressive with it?
Azcanta, the Sunken Ruin certainly can’t, but Search digs a card deeper every turn. It proved to be better to never flip Search as a result.
That’s exactly what I’ll be writing about next week. The power of multiple tutors in one deck really snuck up on me.